Configuring data sources for dbt
sources.yml describes how to reach tables created by ELT service
- name: metrika
database: "{{ env_var('DBT_MSSQL_DATABASE') }}"
schema: "{{ env_var('DBT_MSSQL_SCHEMA') }}"
description: Yandex.Metrika
tags: ['metrika']
tables:
- name: sessions_facts
identifier: metrika_sessions_facts
- name: goals_facts
identifier: metrika_goals_facts
- name: purchases_facts
identifier: metrika_purchases_facts
- name: devices
identifier: metrika_devices
- name: goals
identifier: metrika_goals
- name: purchases
identifier: metrika_purchases
Mind the database and schema keys. They might vary between projects and deployments so they are configured as environment variables. I will show you where they get actual values a little bit later.
Identifier key is the full name to reference a source table in a database, while name key works like an alias for referencing a table in dbt code. It comes pretty handy if you have long table names.
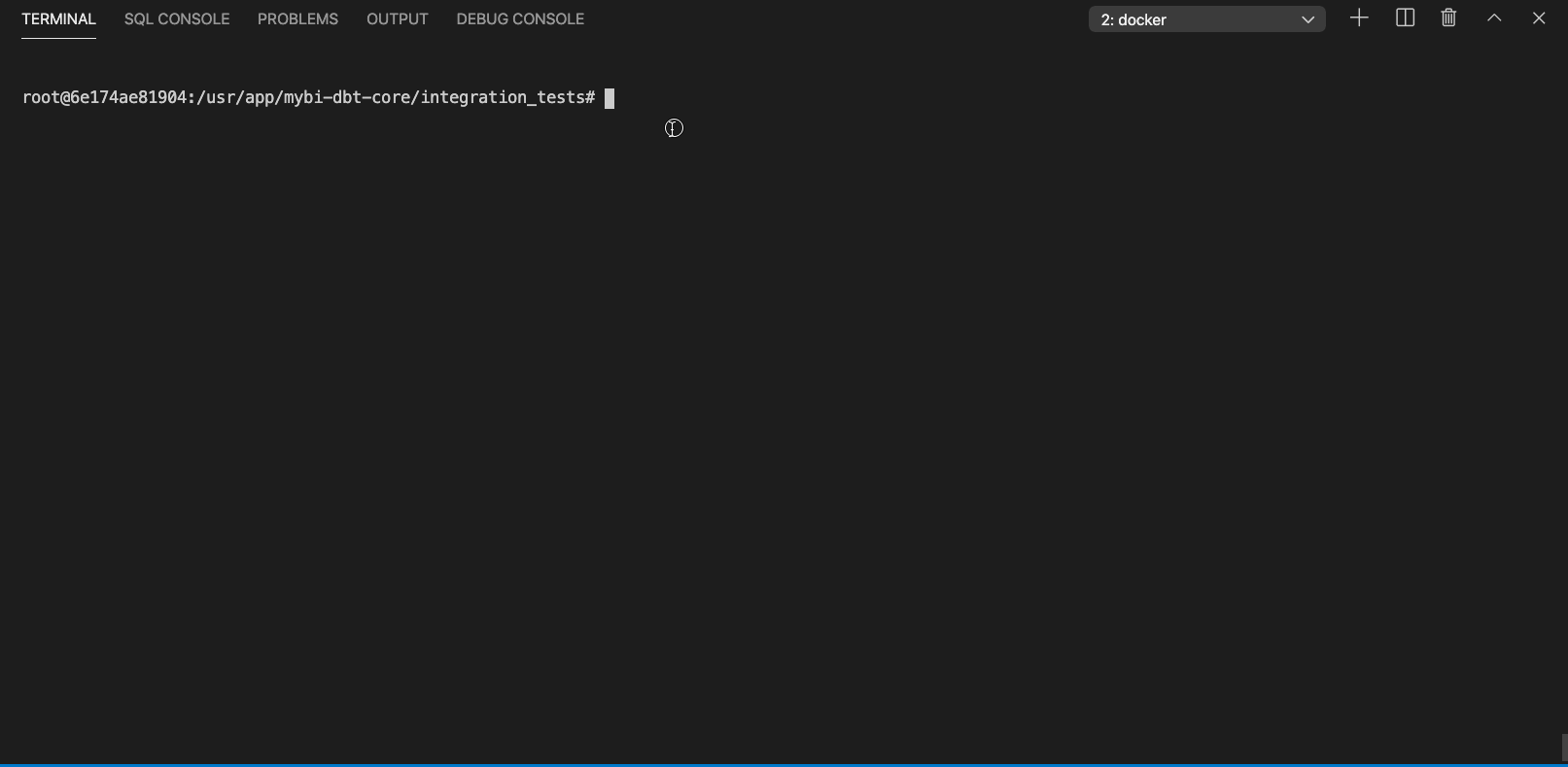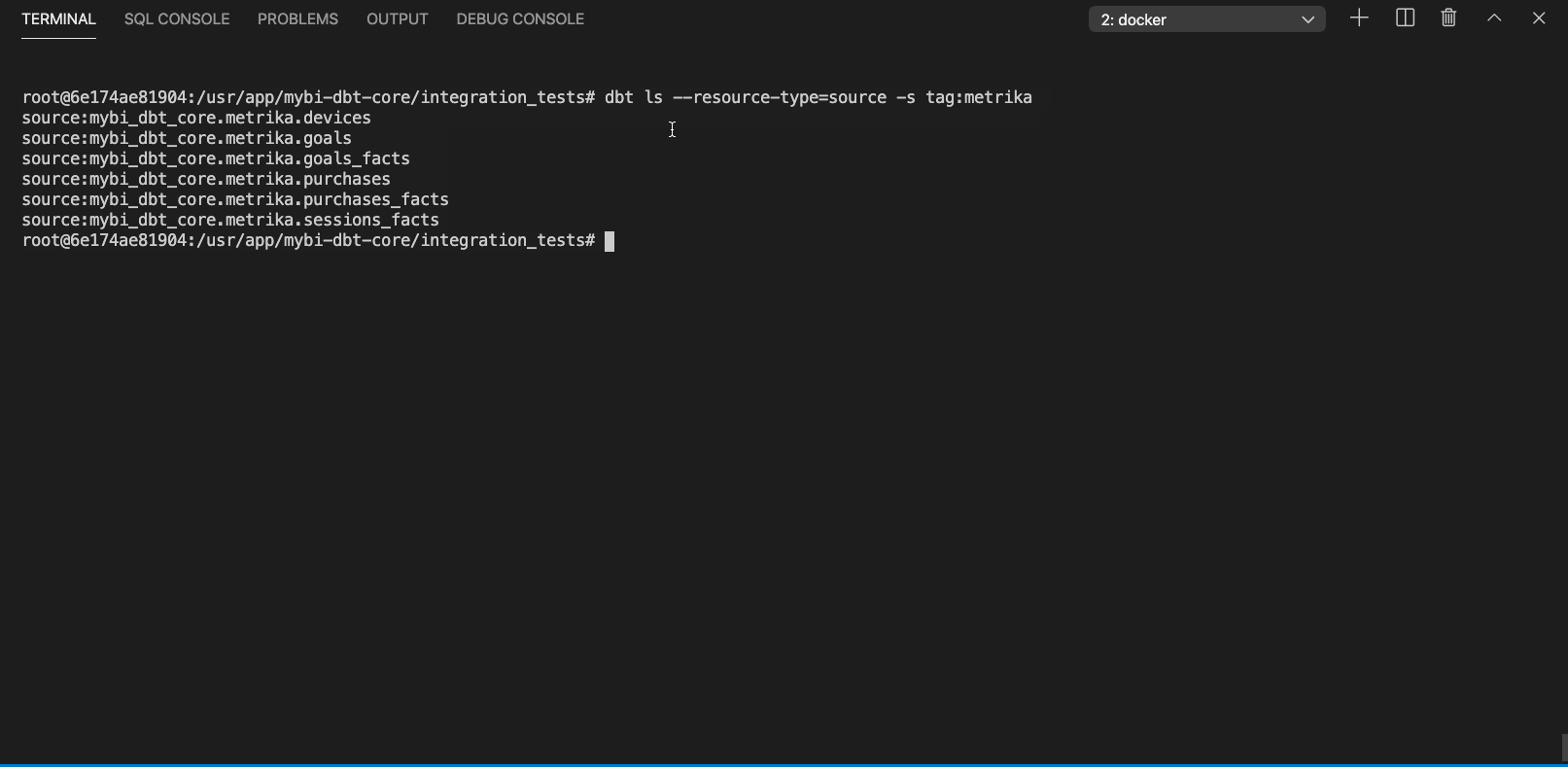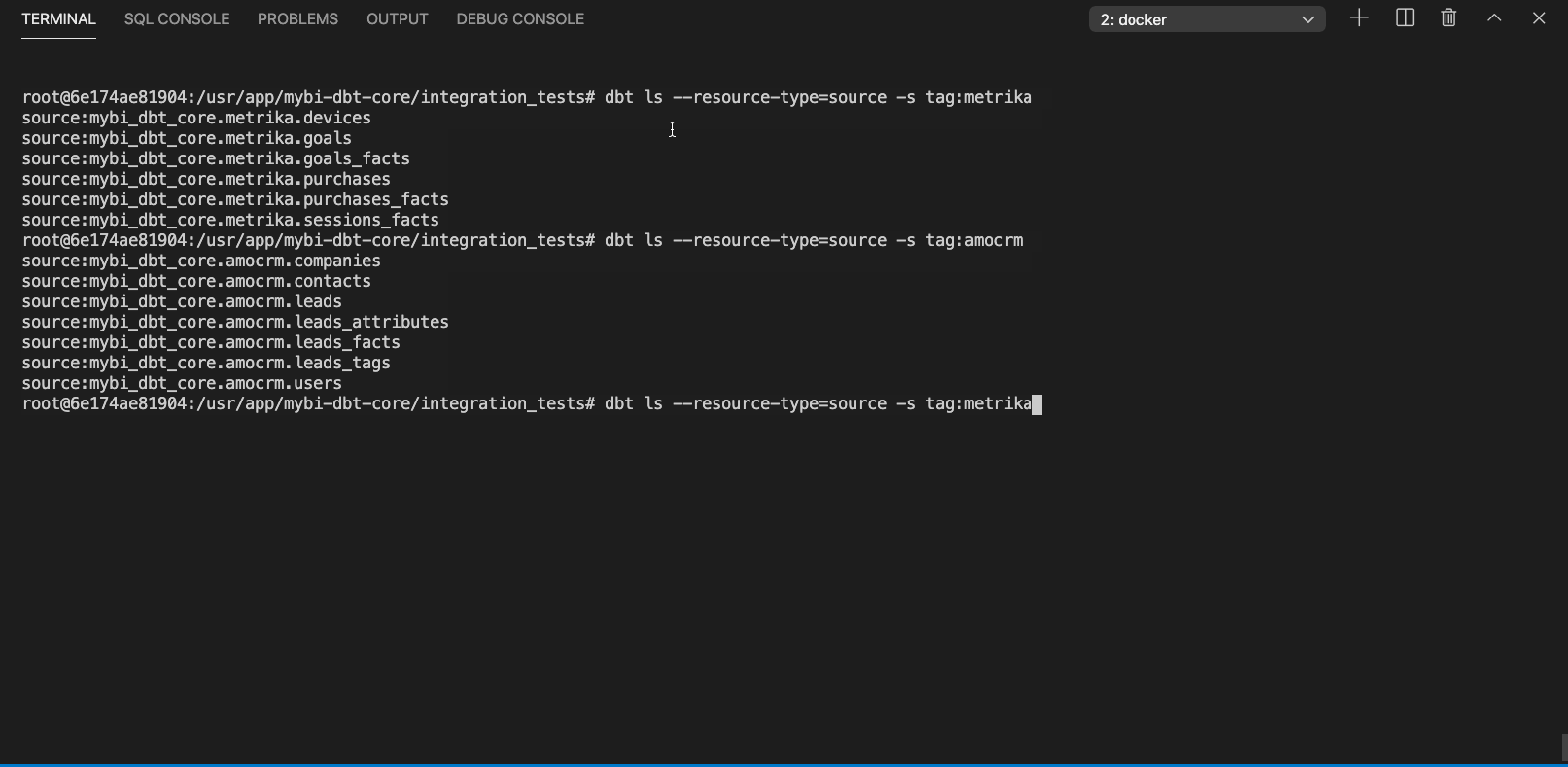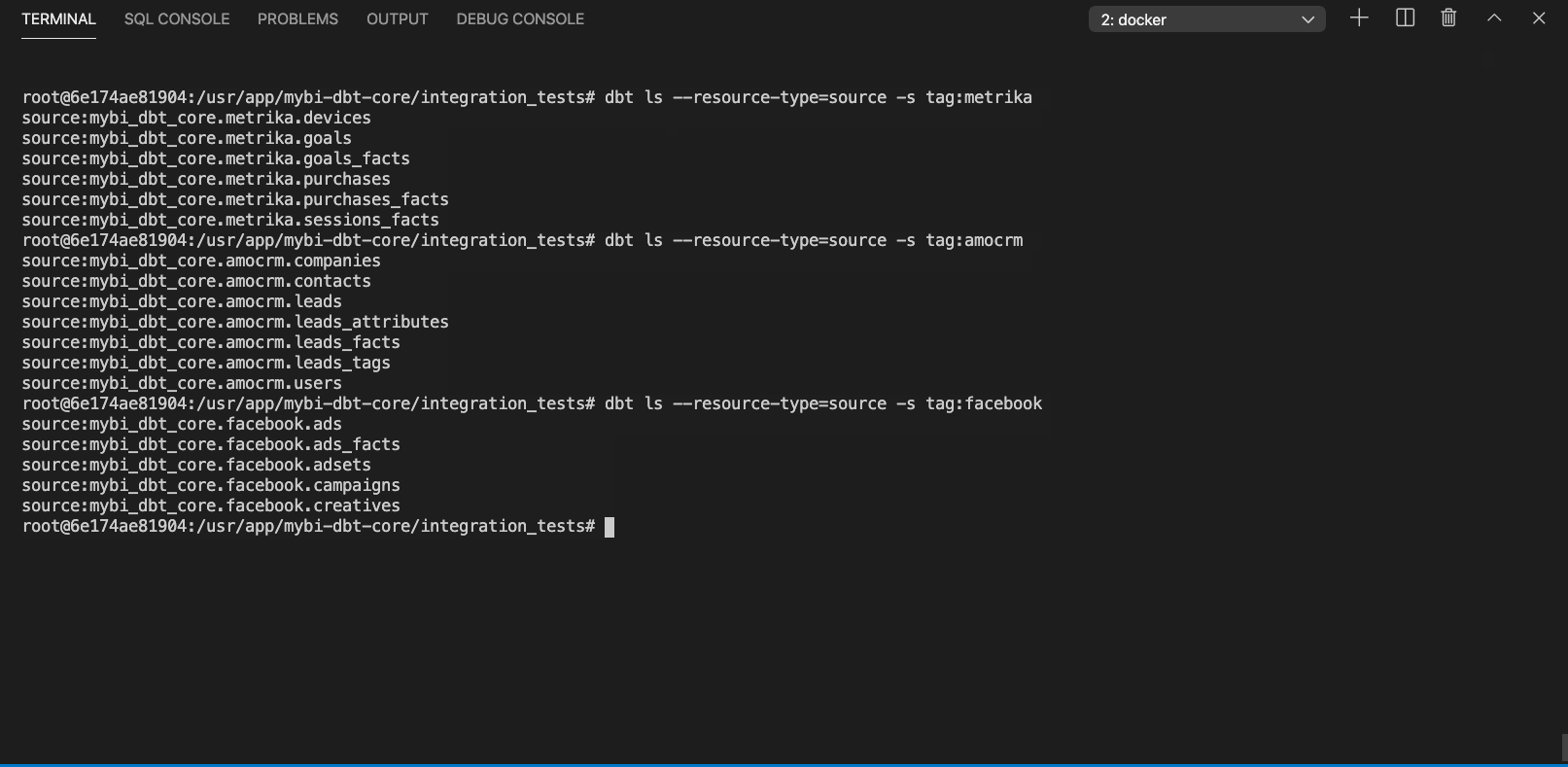
By labeling sources with tags you can select, run or test certain parts of your DWH, for example you might want to rebuild models depending on a particular source after fixing a bug.
Listing particular sources with dbt ls command looks like this (click to expand):