Establishing integration tests and ci
Establishing integration tests and CI
I find it pretty hard to build on top of the CORE DWH module if it is not stable enough. Testing of the whole module during every patch and PR and before you can use it ensures quality and reliability. That is where Integration tests and CI come essential.
First I will spin up a MS SQL Server instance in a docker container to perform real queries on it.
version: '2'
services:
mssql:
image: mcr.microsoft.com/mssql/server:2019-latest
environment:
ACCEPT_EULA: "Y"
SA_PASSWORD: "P@ssword"
ports:
- "1433:1433"
dbt:
build: .
entrypoint: /bin/bash
tty: true
volumes:
- .:/usr/app/mybi-dbt-coreSecondly, I would like to populate source tables with a small portion of data to test on. I just include it into my repository under /integration_tests/data/ subfolder in .csv format. These files are loaded by dbt seed command.
The most important thing here is data in csv files should reflect production source data fully. If there is a relationship between tables then there should be a linked row with the same identifier, otherwise tests will fail.
Example integration_tests/data/metrika/metrika_sessions_facts.csv:
| account_id | clientids_id | dates_id | traffic_id | locations_id | devices_id | sessions | bounces | pageviews | duration |
|---|---|---|---|---|---|---|---|---|---|
| 21600 | 1 | 159250 | 15645 | 165 | 35 | 1 | 0 | 11 | 240.00 |
| 21600 | 1 | 159250 | 726276 | 1 | 35 | 1 | 0 | 3 | 101.00 |
| 21600 | 1 | 159250 | 4821954 | 211 | 34 | 1 | 0 | 6 | 137.00 |
| 21600 | 1 | 159250 | 4821952 | 1 | 34 | 1 | 0 | 1 | 22.00 |
| 21600 | 1 | 159250 | 823634 | 169 | 34 | 1 | 0 | 1 | 15.00 |
| 21600 | 1 | 159250 | 4821936 | 1 | 35 | 1 | 1 | 1 | 0.00 |
| 21600 | 1 | 159250 | 724226 | 346 | 35 | 1 | 0 | 8 | 303.00 |
Things are a bit more complicated, since I have to create a separate dbt project in a /integration_tests/ subdirectory and configure it with module importing from parent directory. But overall it looks nice and neat, the imported module is created as a symlink.
packages:
- local: ../Thirdly, the key idea is to automate my workflow with Github Actions. As a reused module CORE DWH is subject to frequent changes, hotfixes, new sources expansion. I want any change to CORE DWH repo to be fully tested and ensure no errors are introduced.
Take a look at the file dbt_mssql_ci.yml:
name: CI dbt on mssql
# Controls when the action will run.
on:
pull_request:
branches: [ master ]
jobs:
dbt_ci:
services:
mssql:
image: mcr.microsoft.com/mssql/server:2019-latest
env:
ACCEPT_EULA: Y
SA_PASSWORD: P@ssword
ports:
- 1433:1433
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: wait for services to start up
run: sleep 30
- name: dbt mssql action
uses: kzzzr/mybi-dbt-action@v2
with:
project_dir: ./integration_tests
env:
DBT_MSSQL_TARGET: core_ci
DBT_MSSQL_SERVER: mssql
DBT_MSSQL_USER: sa
DBT_MSSQL_PASSWORD: P@ssword
DBT_MSSQL_DATABASE: master
DBT_MSSQL_SCHEMA: core_ciThe workflow is defined like this:
- Triggered on Pull Requests to master branch.
- Spins up an already familiar MS SQL Server database in a container as a service.
- Performs several sequential steps: checking out the code, filling source tables from csv files, running models, testing them, cleaning up.
- Provides context with environment variables (connections details, target database schema name)
kzzzr/mybi-dbt-action@v2 is just a link to a Docker container action I created specifically to address dependencies and versions issues. I will dive into some details on it in a separate blog post.
You can see some historical CI actions run associated with merged Pull Requests. PR #9 qualify macro reference with package name.

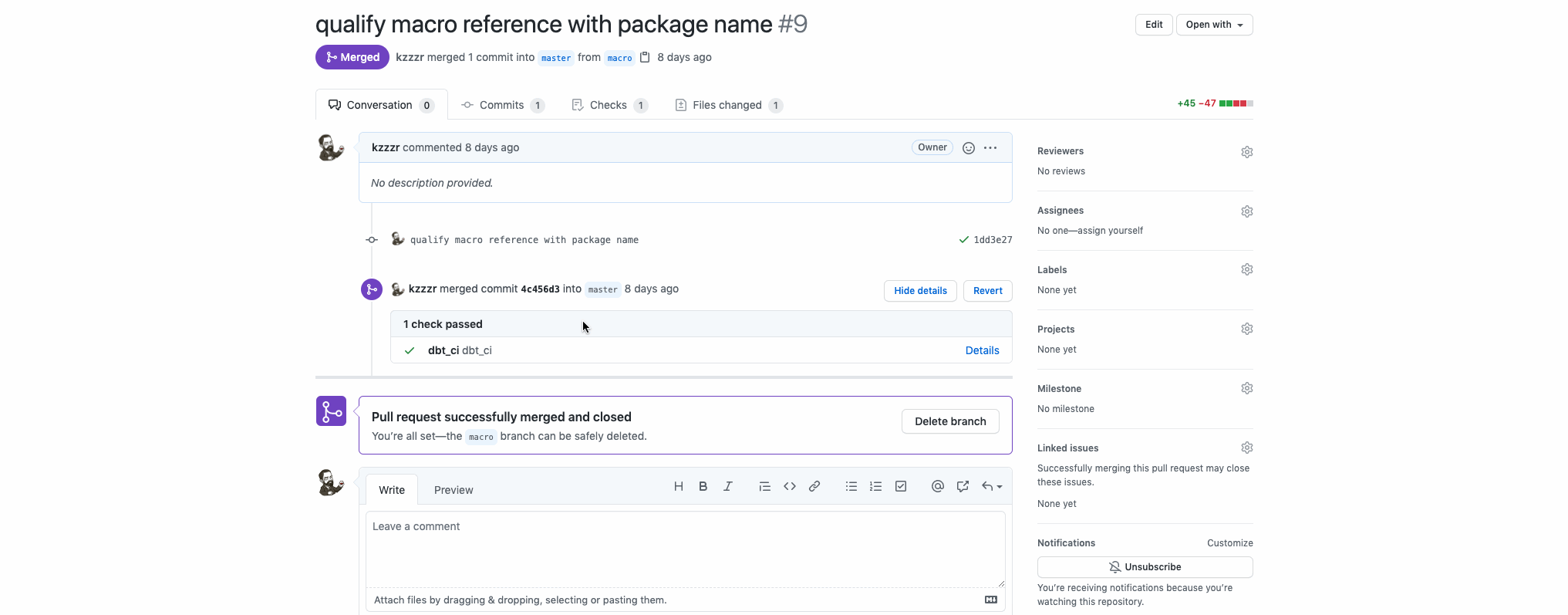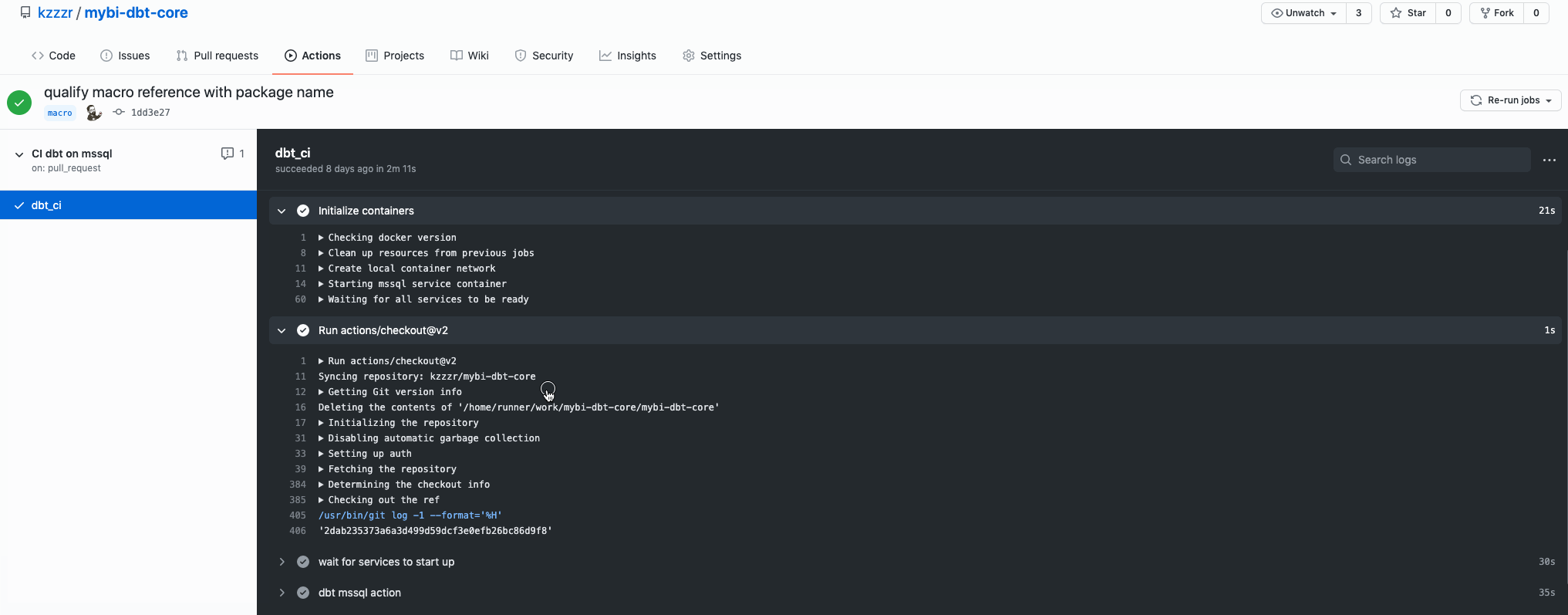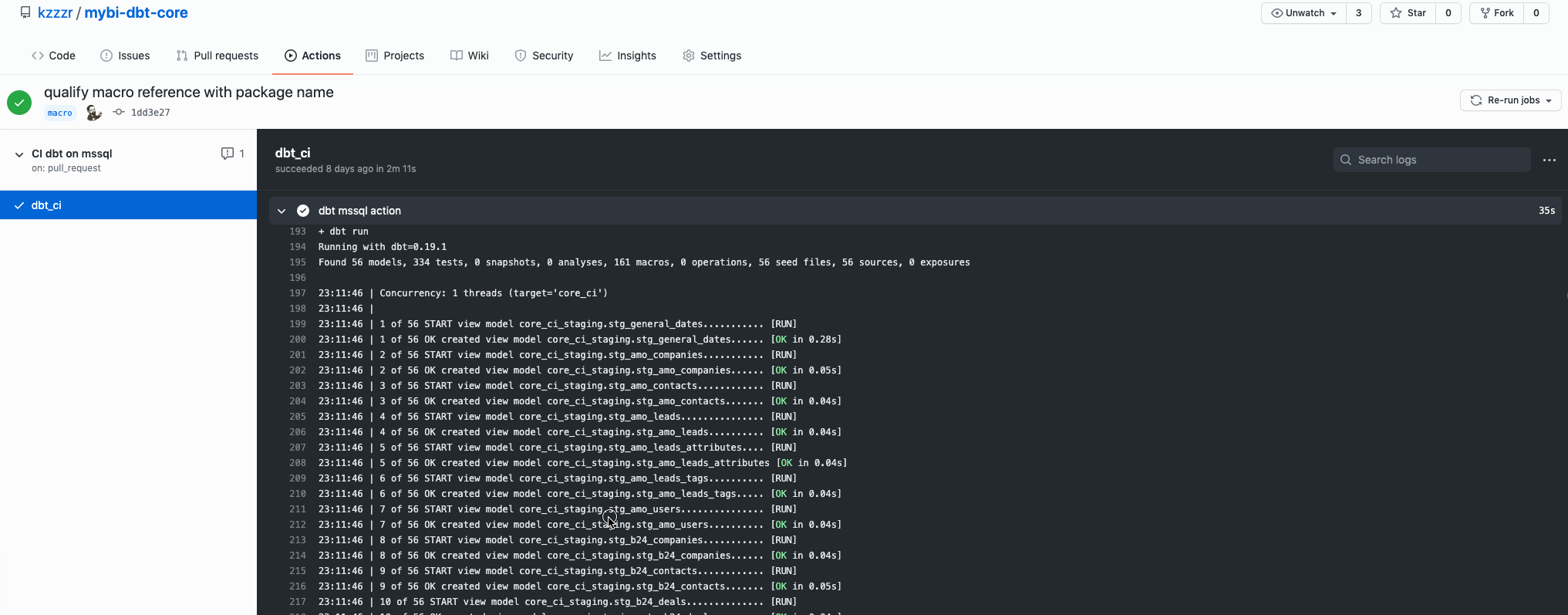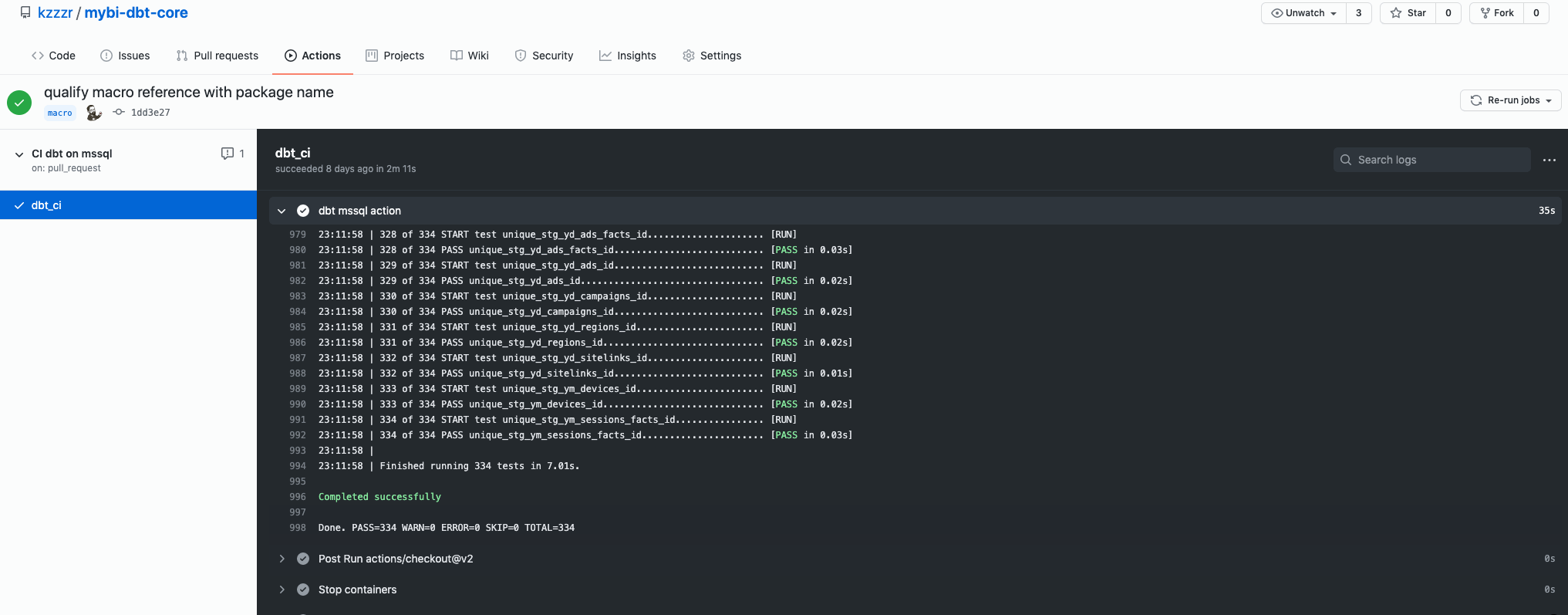
And here you can review the Action logs in detail: https://github.com/kzzzr/mybi-dbt-core/runs/2314717891