
Populating dwh staging area
Models prefixed with stg _comprise the so-called staging area. Source tables are green-coloured, staging tables are blue on the picture below (click to expand):
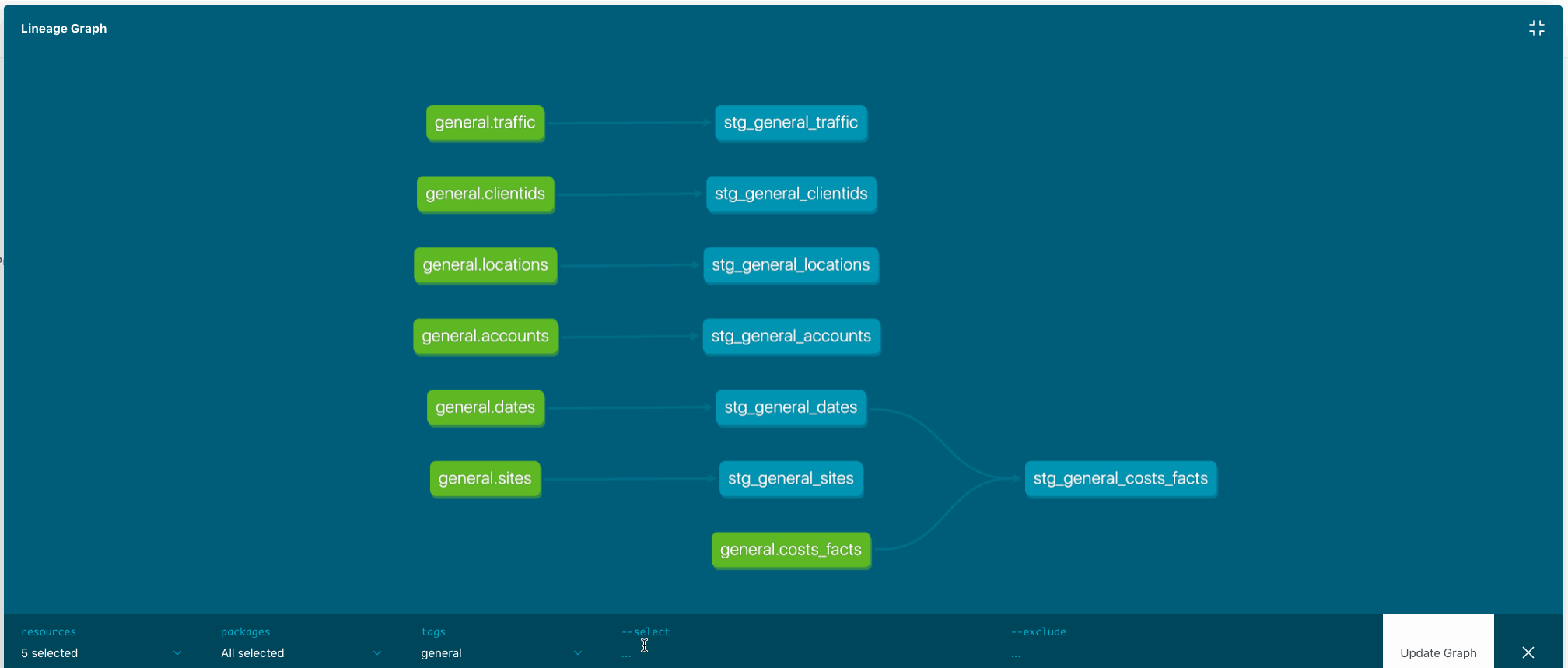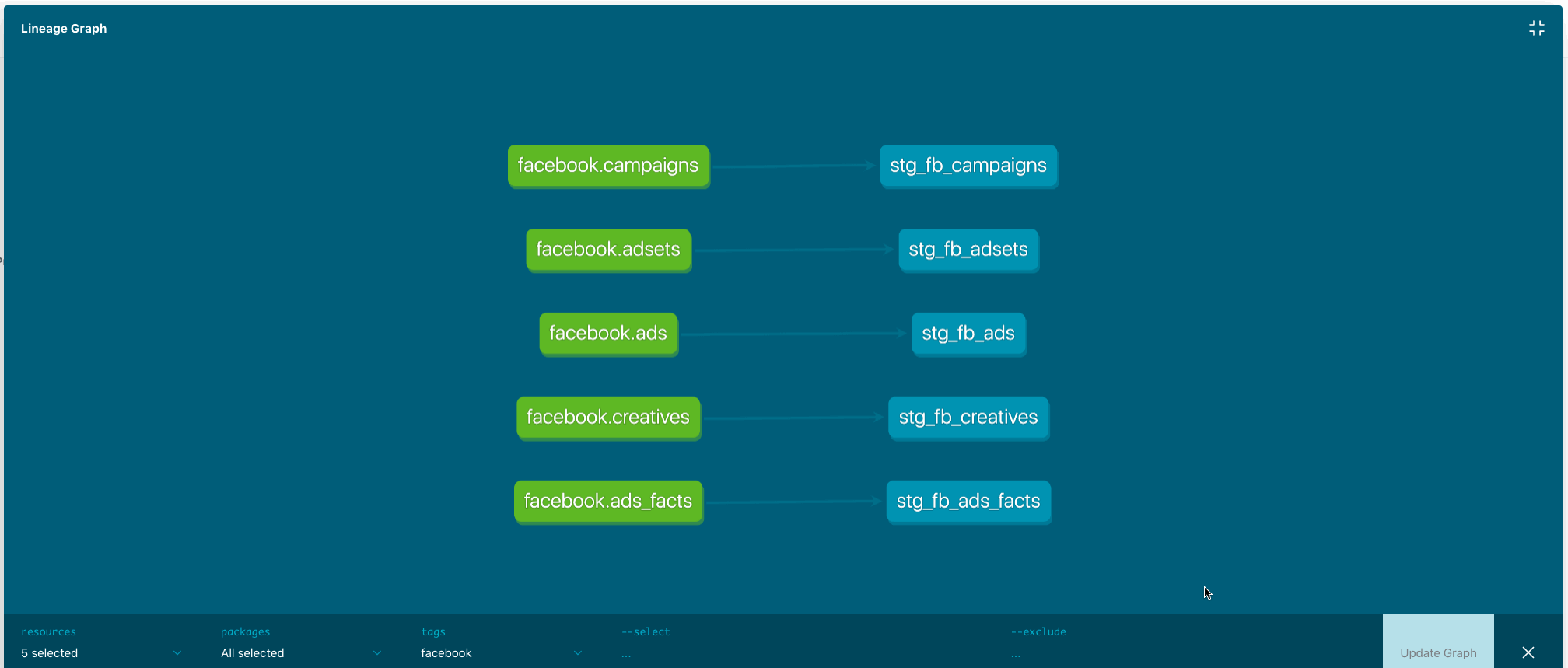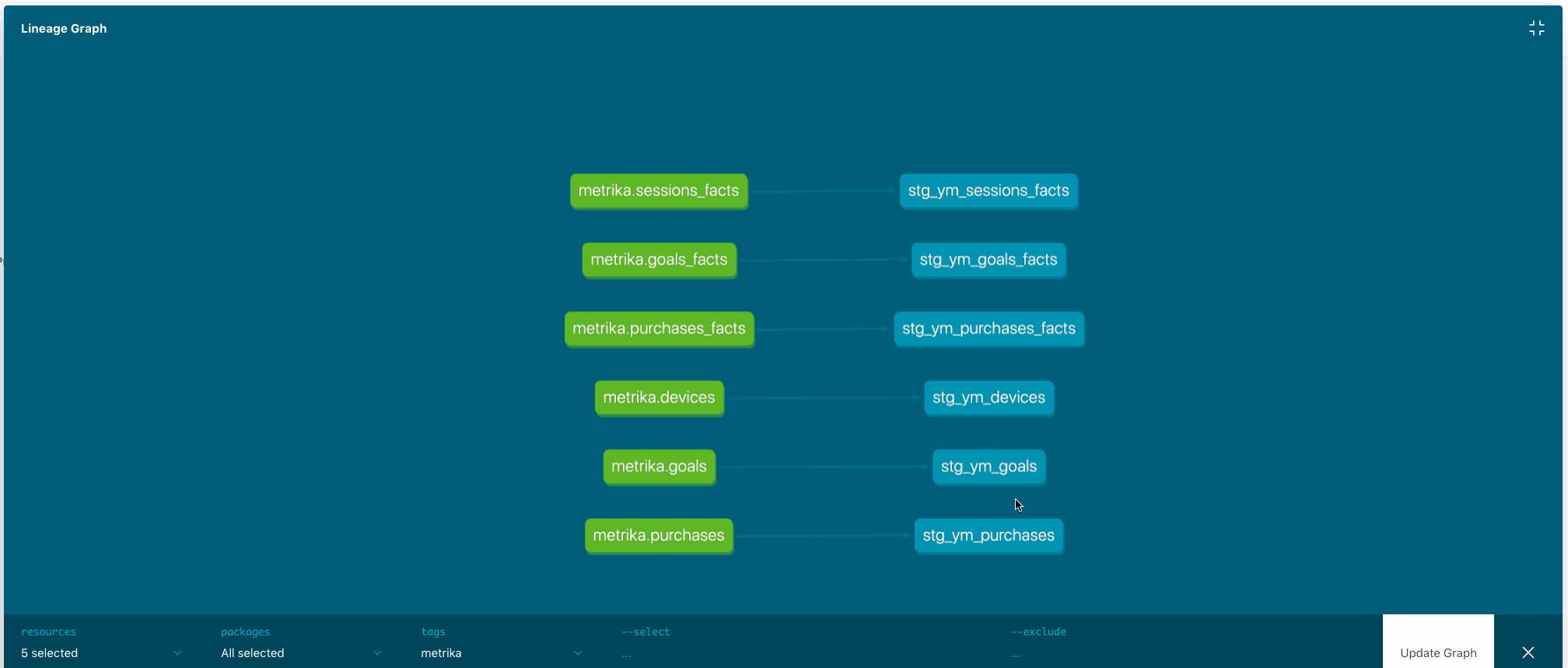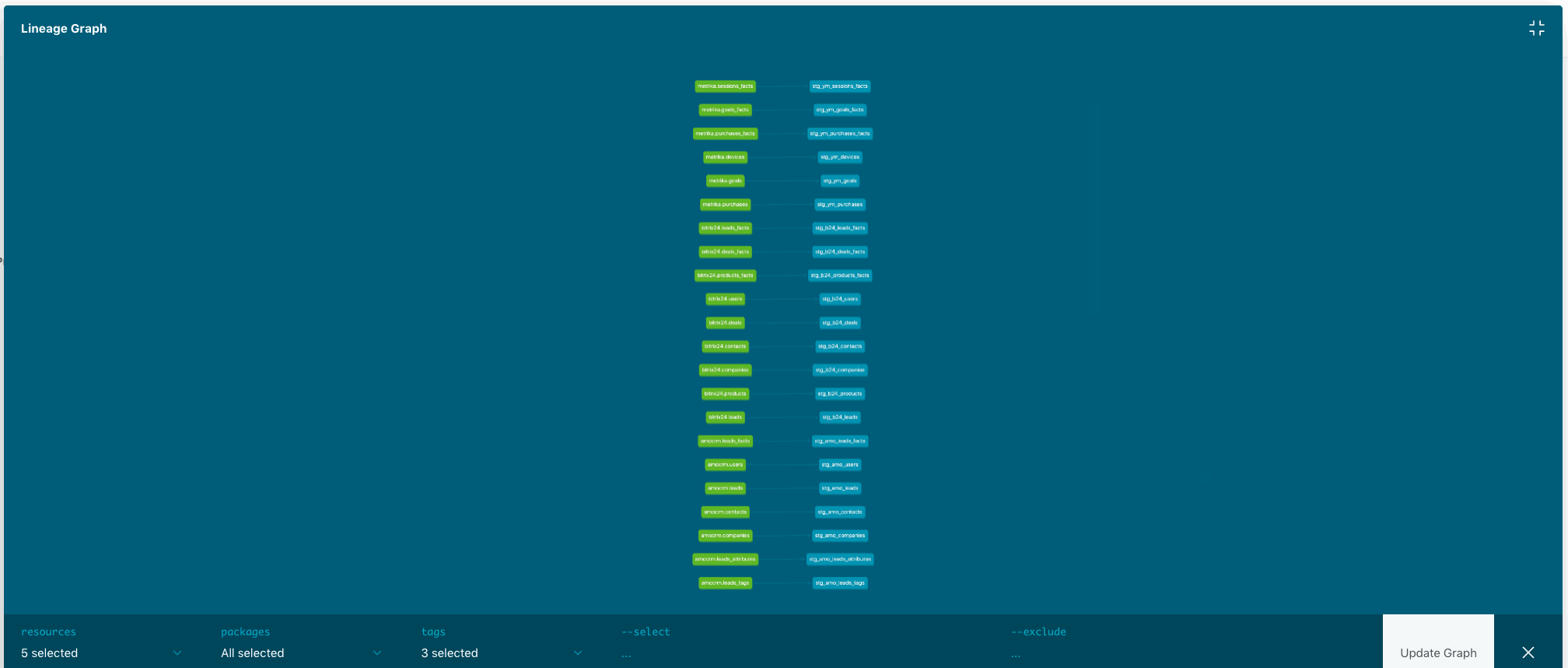
Since I want to use dbt to deploy my projects I would like to build a common ground. In other words that would be staging area pointing to source tables covered with data tests thoroughly.
Let us examine the source code for stg_ym_sessions_facts:
with source as (
select
{{ surrogate_key(["account_id",
"clientids_id",
"dates_id",
"traffic_id",
"locations_id",
"devices_id"])
}} as id
, f.account_id
, f.clientids_id
, f.dates_id
, f.traffic_id
, f.locations_id
, f.devices_id
, f.sessions
, f.bounces
, f.pageviews
, f.duration
, gd.dt
, gd.ts
from {{ source('metrika', 'sessions_facts') }} as f
left join {{ ref('stg_general_dates') }} as gd
on gd.id = f.dates_id
{{ filter_rows(
account_id=var('account_id_metrika'),
last_number_of_days=true,
ts_field='dt'
) }}
)
select * from sourceStaging tables serve the following key purposes:
- Listing available columns
So that any subsequent model could use all of them or specific columns.
- Simple joins are performed
See the ‘stg_general_dates‘ is joined to enrich the staging table with basic time dimension: session date and timestamp. You might also want to add weekday, quarter, date of the week start, quarter, etc.
- Surrogate keys
Are generated where applicable. Macro is used which I will describe in detail later.
- Rows are filtered
Whole logic is implemented in filter_rows macro. Key point here is you may have several source accounts streaming data to a single table, each of them having its own unique identifier. I only want to fetch rows for a specific account (customer).
There is also one major improvement for the Continuous Integration pipeline: using only 3 last days of data to test your DWH before you merge a new patch. I will cover it later.
Other things you can do in the staging area:
- Rename your columns to align different sources
- Cast field types, cast timezones (local -> utc)
- Deduplicate rows if your ELT service doesn’t do so